- Published on
Why you shouldn't use the Repository Pattern (.NET)
Introduction
So you’re writing code, and you surely follow the Clean Architecture principles with all its glory. Repositories were introduced long ago and are getting normalized and marketed as a "standard" for you to abide clean code. We've all seen people quoting Martin Fowler's take on it, or slamming Domain Driven Design (DDD) books left and right to justify that new norm. This post aims to describe the underling concept and its potential problems/pitfalls, while providing simpler alternatives and guidelines to consider.
Repository Pattern
In a nutshell, the Repository pattern consists of abstracting our Data Access layer/objects with a dedicated class/layer as shown below.
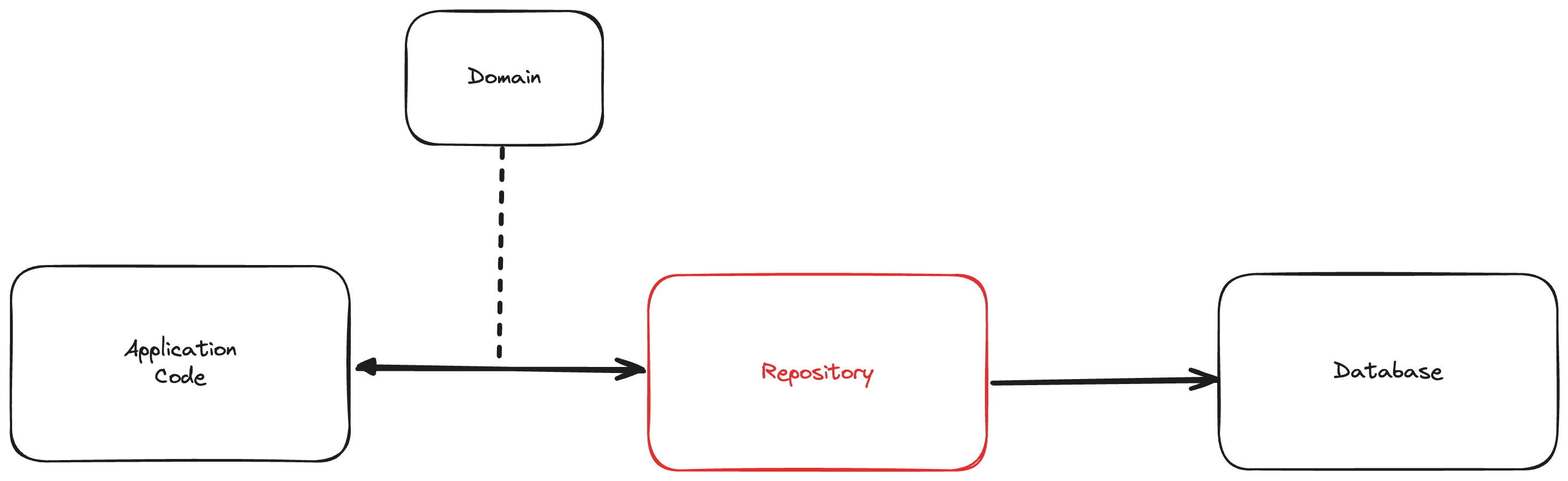
This new layer sits between your Domain/Application logic and the database by communicating with the database (reading or writing) + mapping the database responses in the domain classes. This translation centralizes the handling of a given domain object allowing it to evolve independently. A typical example would be an ECommerce website, a user can create an account, login, and purchase some items. You'll have a version of an IUserRepository that accepts and emits a domain User object and manipulate the database:
public interface IUserRepository
{
public Task<User?> GetUserAsync(UserId id, CancellationToken token);
public Task<CreateUserResult> CreateUserAsync(User user, CancellationToken token);
}
Which will be used in the main application/domain layer independently:
public class UserAccountHandler
{
//...
public async Task<IResult> CreateAccount(User userToCreate, IUserRepository userRepository, CancellationToken token)
{
var userId = userToCreate.ComputeId();
if(await userRepository.GetUserAsync(userId, token) is not null)
return ConflictResult.On(userId);
var createResult = await userRepository.CreateUserAsync(userToCreate, token);
return createResult.Success
? CreatedResult.From(userToCreate)
: ErrorResult.From(createResult.Errors);
}
}
The last bit of the puzzle would be the implementation of the IUserRepository, which is mostly irrelevant. Just adding the simplest option for completeness:
public class InMemoryUserRepository : IUserRepository
{
private static IDictionary<UserId, User> _store = new Dictionary<UserId, User>();
public Task<User?> GetUserAsync(UserId id, CancellationToken token) => Task.FromResult<User?>(_store[id]);
public Task<CreateUserResult> CreateUserAsync(User user, CancellationToken token)
{
_store.Add(user.ComputeId(), user);
return Task.FromResult(new CreateUserResult(true, null));
}
}
(Alleged) benefits
UserAccountHandlerdoes not know anything on how we're storing and retrieving the data (Users), it only cares about the business logic.- To test
UserAccountHandler, we can Mock or Stub theIUserRepositoryand test the Handlers logic without needing to spin up infrastructure. (This is assuming the actual implementation is using a real database) InMemoryUserRepositoryis centralizing all the read/write patterns for theUserentity, you don't need to skim 20 files to know who's using what (which index, which query etc...).- If you change the underlying infrastructure, you will not touch working application code and only extend things via a new implementation of the IUserRepository. Say another
SqlServerUserRepositoryinstead of theInMemoryUserRepository.
A real world truth!
Benefits stated above are correct, however the practical world is very different for the majority of the use-cases, particularly if you're using an ORM (Entity Framework, Hibernate...) making the general advise of "have a Repository everywhere" not true. Whys below:
Centralizing Data Access Code
Using a Repository merely to centralize your database communication code is generally not worth it. You can achieve the same fate by solving this problem like how you do generally. DRY is the root of all evil, but that's worth a ramble on its own. You can centralize your queries and access in Extension methods, or standard static functions.
- This might still be considered a "layer", but you'll have a bit of a "loose" contract which you can break, change and evolve easily while still keep it central.
- You can have your DB setup and wiring in the same file as well, which is more central than an Entity sliced Repository.
- Things like indexes, views or stored procedures will be in the same file. Don't think the application code is only dependant on your queries. You'll be surprised how much you need to tweak and configure things outside of your query for the code to work correctly.
- You only group what you need, having a Repository enforces you to add things that are used once and extending/evolving that contract every time. With every unnecessary addition, you're breaking the core logic and splitting it across multiple files, which would be terrible for people working/reading that code.
A great example of this in action is the Dapper micro-ORM, which is build around extension methods. Simple, if you're doing a GetUsers in 2 different places, wrap that code in a single function... :)
Swappable Infrastructure
This is the biggest myth that people use when creating Repositories. In any organization, the infrastructure you choose is mostly linked to factors outside of your control:
- You’re tied to the technology stack of the company you are in and you can’t just do as you please.
- You’re tied by the on premises or cloud constraints of your app (Pricing for example).
Or you actually have this freedom to choose your most optimal database, isn’t that great? It surely is, but let’s think this through… To persist your so called 'business domain', you will start to think on the ‘How should I store my entities’. This will also vary depending on the database you are using:
- If you’re using SQL, you will start drawing links and relations to navigate your fixed tables.
- If you’re using DynamoDB or CosmosDB, you will think about your partition and sort keys, how the entities should be grouped and distributed.
- If you’re using MongoDB or anything else really, you will find yourself between the two.
Even though there is a lot of database providers, your plan to concept your database may will vary depending on the infra you use. Even if you think you can "abstract this logic from your business/application code", changing your database provider will surely make you change and rethink a lot of your application code in general. A simple example would be adding pagination (with specific pages) to entities stored in DynamoDB. You don't have tons of options here, and in all of them, your entire application code, logic or your entire user journey will change. Some options you'll probably think of:
- (1) Adding a new async ElasticSearch/OpenSearch event source integration via DynamoDB Streams.
- (2) Migrating to a relational database, PostgreSQL might be beneficial for filtering and tweaking, but counting rows us a harder problem than it seems. Here's a nice article that surely explains it better than i do.
- (3) Tons of other options, including de-prioritizing having specific page numbers, or the entire feature, or rethinking the overall UX :)
Note that's unrelated to supporting multiple databases which is another beast. The point here is that simple code should be easily teared down and swapped on incrementally, it's not the data access layer that will withhold or save your migration if it ever happens.
Contract Rigidity
Hard and 'dummy' contracts are a pain we've all felt. How many times did you have to add a function to 5 interfaces just to be able to support a new access pattern.
Another case is when you start "cheating" and hacking your way around those interfaces to make things work. That's when you start to have a GetUser and a GetUser2, GetUserNoName or any other combination.
I'm sure someone will shout "You're doing it all wrong"! You should use the Specification pattern on top of your Repository to make it easily extensible. This fancy pattern is not free, in fact nothing is free in software.
Specifications comes with a ton of complexity, re-inventing the wheel, wrapping each and every object with a predicate that you would translate.
There's a tipping point of which every software engineer should realize of "oh -- this might be too much 🙁". Surely most will build it anyway for the sake and fun of it, but we should always be aware and intentional on the battles we're picking, what we're losing and gaining with each pattern.
Ease of Testing
Testing might be the only applicable argument in edge cases. We're all aiming for reliable, fast behavioral tests.
In any complex systems, the requirements or test cases are enormous for you to test everything on a high level (E2E, Synthetic tests). What you're probably aiming for most of the time is to have a fast feedback on your tests, making them build and run locally without any actual infrastructure. This is a noble and shiny goal, but there's a lot of things to try before using a Repository.
The tests most importantly need to be realistic. Which in itself is a big risk when using a Repository. To run your tests, you'll mock/stub that interface and make it return your expected outcome.
Sadly, this hides a lot of problems and edge cases that can happen on the layer itself. Things like indexes, queries won't be tested. This wouldn't be a big problem if you're adding integration tests on those points:
- If you're using an ORM, an in-memory or SQLite for SQL users is a no brainer, it allows a more realistic test (even if its not fully realistic and will not spare you the integration tests), will spare you less code and setup as your actual code remains untouched.
- If you're using an SDK or a nuget to call something external, mocking/stubbing it without touching your actual code can be a more reliable option. Think of having your fake
IAmazonDynamoDbor yourFakeMongoDbClientetc... There's also tons of nugets which have done that already so you don't have to.
A Repository here isn't a very bad idea, just that there's a lot of simpler and more effective solutions to consider before going that way. Keep in mind that any of those won't spare you tests against your actual resource!
Ending notes
One of the most challenging aspects of designing a system from scratch is the countless possibilities you might have to do a simple thing. Instead of aiming to use the new, shiny or popular pattern, push your most simple code, reflect on a specific problem you have and look at patterns that can help you solve it.
Always experiment, formalize and document the drawbacks that you're introducing with each solution. You would be surprised how simplicity can unburden and relief a given team!